

2010年,《经济学人》上发表了一篇长达14页的专题报告《数据,无所不在的数据》,为了突出变化,科学家、工程师们还对这个现象取了一个新名字“Big Data大数据”。
次年,麦肯锡也发布了重磅报告《大数据:创新、竞争和生产力的下一个新领域》。2012年达沃斯论坛上也设置专门的议题。大数据,快速普及,成为国与国之间博弈的新角度,成为公司开拓新业务的方向,也成为社会舆论的焦点。
但火了一段时间后,普通民众发现大数据好像并不能迅速改变什么,逐渐降低了关注。然而,数据的作用却在悄然发挥,比如更个性化的推荐、就医等流程优化、城市治理等等,以及成为我们数字战略的重要原材料。
人们似乎很容易对当下高估,却又低估长期的趋势。
2023年初ChatGPT出圈后,大模型,也成为舆论焦点。似乎带个大字,就是不一样。国际、国内巨头都纷纷加入了大模型的竞赛。这场竞赛会如何开展?是否会像大数据一样,历经兴奋与平淡,却带来影响深远的变化呢?
模型的进化
大模型和模型相比,只是加了个大字,为什么就这么令人兴奋呢?
解答这个问题,要从它怎么来的说起。由于自然语言理解是人工智能的核心难题之一,因此我们也从自然语言处理为线索来看。
在1956年美国达特茅斯学院的暑期会议期间,参会人员首次决定将像人类一样思考的机器成为“人工智能”,随后世界第一座AI Lab实验室建立。此时人工智能的主要路径是“规则”。
所谓规则,就是人们从数据中抽离出知识,进行归纳后将规则建立起来,让计算机执行规则,从而理解人类语言。但人类语言实在太精妙了,比如“我一把就把把给把住了”,一个字、多个意思,这完全是机器不能理解的,路径需要进化。
1993年起,人工智能进入了“统计机器学习阶段”。做法是人工将各种语料标注好,然后利用数学方法统计出各种语料在各种结构下出现的概率。经典的例子就是苹果,假如出现80%的次数都是手机,而不是水果,那么在实际应用中,就先按照手机来理解。
这个阶段,最辛苦角色之一就是数据标注员,标注数据量达到了百万级别。大概又发展了十年左右,新的阶段“深度学习”开启了。
深度学习使用“向量”来表示语义,向量里的值表征该语料具有该特征的概率大小。通过向量就可以计算语料的相似度。标注数据量达到了千万级别。
在2018年左右,深度学习又迈向了“预训练阶段”,通过预训练、微调等方式,数据量扩大了5倍左右。OpenAI发布了GPT-1,谷歌发布了BERT。颇为“开天辟地”的Transformer也横空出世。通过注意力机制,可以并行、快速处理信息。
此时的AI不再过度依赖标注好的数据,而是可以通过做填空题、获得人类反馈等方式,获得更快的训练。惊艳的OpenAI也是基于Transformer进行研发应用。
随着模型参数不断扩大后,人们惊讶地发现,模型具备了以往小规模不具备的能力,例如更严谨的推理等,甚至学会了人类的幽默感,这就是目前还不知道原理如何的“涌现”。
历经规则、统计机器学习、深度学习、预训练等阶后,人工智能终于展现出了极高的突变性、更强的自主学习能力、以及更广的通用性。这都宣告着,人工智能范式革新,大模型时代来了:通过大模型结合人类反馈,从而高效解决海量开放式任务,不只是语言,而是多模态。
新时代来临,海外巨头惊艳亮相时,我国企业也并不是“蹭热度”。也许实力和海外有差距,但投入也是扎实的。
2014年,商汤科技成立,第二年就在素有“计算机视觉奥林匹克”之称的ImageNet赛事中夺魁。而从2018年起内部开启了大模型和大算力的研发,和海外巨头几乎同时起步。依靠人才济济的团队、长期坚定的研发投入、以及产业应用经验,商汤也在2023年4月发布了“日日新SenseNova”大模型体系。

科技从来不是一蹴而就,而是曲折中不断摸索。大模型,和模型相比,似乎只是多了一个“大”字,但这一个字,就是数以万计的科学家、工程师们,六十余年、两万多天的付出。
怎么定义大?怎么定义好?
大模型,该怎么定义大?怎么定义好?
咱们普通人肯定会用模型的参数量来定义、区分模型,比如千亿肯定比百亿好。但实际上,模型的能力要综合考量两个要素:参数量、用来训练的数据量。
参数量和数据量的乘积,也就是计算量,这才是区分模型能力更合适的标准。如果进一步拆解的话,就是GPU数量、乘以大规模并行计算的效率、再乘以运行的时间。这就是新时代下,算力、算法、和数据的新公式。

这个公式,既是行业未来发展的脉络,也是业内公司彼此较量的“武器库”。
算法就像学武功时的天分一样。普通的大模型,通过勤奋和努力也可以达到一定水平,但需要有师傅一招一式地演示、传授,一旦没教的就不会了;而优秀的大模型,并不需要完全的一招一式教,而是给予合适的心法、在关键地方的引导,就可以学会招式,甚至可以自己创造新动作,就像张三丰自创太极、成为宗师一样。
如果只是在舞台展示,会发现学太极和创太极的似乎水平一样,动作都很规范,但到了实战中就差距显著了。因此,评价模型不能静态。
好模型首要做法是依靠优秀的人才,并吸引海内外先进知识。目前,商汤形成了全栈大模型的研发体系。业界戏称“模型很大,GPU放不下”,因此商汤采用了分布式的训练优化,包括数据运行、模型并行的优化混合精度优化等等。
其次,在研发过程中,要用更丰富的场景和开放任务去检测模型能力。这既是一个思路,也是商汤基于行业应用多年沉淀的优势。
高质量数据是稀缺的。就像国内科学家们经常吐槽,中文数据被广告污染太严重了,高质量自然语言数据必然会逐渐稀缺。今天已知最大语言模型消耗的数据量是2万亿个token。而据统计,人类文明产生的高质量语料数据一共是9万亿左右。因此,随着倍数往上走,很快就会面临着高质量语料被消化完的局面。
一个解决方法是人类不断继续生成高质量文本内容,但写的速度肯定比不上机器学的速度。另一个途径是多模态,增加听觉、视觉数据。尤其视觉方面,人类捕获信心80%都是靠眼睛,如果机器也可以如此,那就可以更好理解世界。
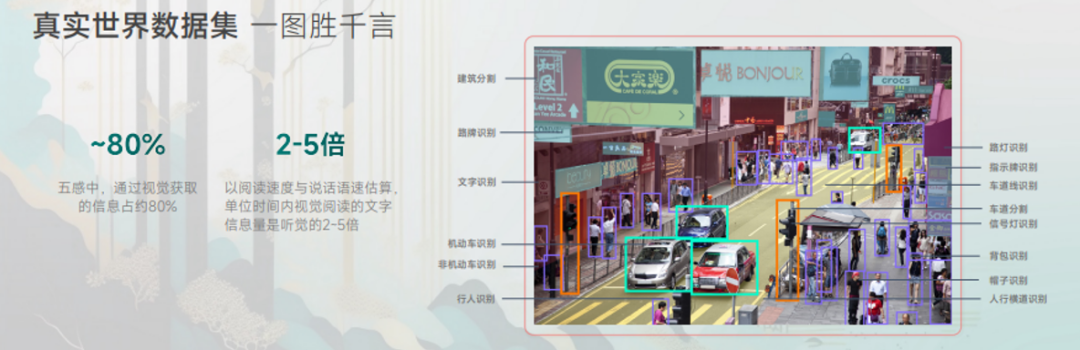
在视觉方面,商汤依靠智能城市、智慧商业等业务,在视觉领域也积累了大量高质量真实世界的视觉数据。2019年,商汤首次发布了10亿参数的视觉大模型。2021年~2022年,训练了百亿参数规模的超大视觉模型。2022年,发布了320亿参数的视觉大模型,为全球前列。
除了高质量的真实数据,数据的丰富性也很重要,尤其是稀缺、复杂场景的数据在实际中很难获取,比如自动驾驶里的极端天气、灾害、事故等的数据等。商汤基于日日新大模型体系,可以进行生成,然后基于生成的图片,用明眸平台进行自动标注,这样就可以补充相应的训练数据,提升在复杂场景的能力,得到更好的效果。
高阶算力更是稀缺。过往的10年,最好的AI算法对于算力的需求增长超过了100万倍。算力要看多卡并行状态下的有效利用率即实际算力,也要看够持续稳定运行的时长。
芯片并不是商汤的主业,也很遗憾我国芯片先进制程还需要投入许多精力来进行研发攻关。幸运的是,商汤也是“采购达人”,早早做了准备。目前,商汤AI大装置有2万7千块GPU芯片卡,可输出5000P算力,支持20个千亿参数超大模型同时训练,并且支持最大4000卡并行单任务训练,可持续7天以上不间断稳定训练。
算法、数据、算力,就像天赋、招数、内力一样,各条线都要发展,才能更好行走江湖。
大模型如何发挥功效?
就像开宗立派,是为了造福武林;模型更大,并不能只是花头,而是要真正有用。鉴于大模型时代刚开启,我们对应用可以做展望,至于如何落地仍然需要各公司、从业者们继续探索、努力。
比如,自然语言可以提高人机协作效率,成为得力助手。
内容行业,可以编故事、写诗词、写营销方案、甚至做心灵指导,解读PDF文档。就像国内一家领先的营销公司,就发布邮件称,计划采用GPT来完成创意设计、方案撰写、文案撰写等业务。医疗行业,可以能提供导诊、问诊、健康咨询、辅助决策等多场景多轮会话。开发领域,可作为编程助手自动进行程序生成。
比如,生成式AI应用,可以成为视频内容的制作和生成工具平台。
在商汤的技术开放日上可以看到,通过秒画,可以轻松地创作高质量的艺术作品;通过如影,可以实现高质量、无门槛、多风格的数字人创作;通过格物、琼宇,可以实现高效、可交互、可编辑的物体和场景生成及漫游。而这些人、物、环境,都可以在数字空间中无缝连接,大幅提升短视频、直播产业生产力。
商汤在发展期间,积累了丰富的行业know-how,对各行业问题的定义积累了洞察和技术,可以反哺大模型在各行业领域应用能力的提升。
比如,在自动驾驶领域,关于车辆是否应该减速是个重要判断。在现有的AI系统中,首先进行物体检测,得到检测框,然后进行文字识别,最后做出决策判断。所有这些模块都是预先设计好的任务。
而在大模型时代,做法有了提升。在商汤“日日新SenseNova” 大模型体系的展示中,给定图像后,可以向人工智能提各种问题,比如“这个图标是什么意思?我们应该做什么?”。人工智能会给出答案和中间的推理过程。看到有限速30公里的铁牌,就会推理出来,这是学校区域,会有学生活动。因此,需要降低速度。
如果说以上的应用,是许多AI都可以完成的,那么对商汤而言,还有一个更具有特殊性的业务“MaaS”,也就是大模型即服务。

自动化数据标注,可实现智能标注,带来近百倍效率提升。大模型推理部署服务,可将大模型推理效率提高100%,实现快速部署应用。大模型并行训练和大模型增量训练服务,能够帮助客户快速结合相关领域知识,训练不同的行业大模型,实现千行千面的模型开发,并将增量微调成本降低90%。
大模型时代刚刚开启,而商汤的通用人工智能大模型体系也还在进化。未来会覆盖包括视觉感知、语言理解、内容生成和推理决策四大方面。
进化和坚持
未来学家凯文·凯利在经典著作《失控》中提出:世界的物质,可以打通,我们迎来了生物和机器的联合,连接成一个庞大的进化体。
在过去十几年,大家还常有疑问。但ChatGPT的惊艳亮相,让大家都开始重新思考进化体的话题,甚至担心人类的未来。因此,最近也引发了对GPT停止研发的呼吁。
人工智能的发展奇点何时到来,我们并不清楚。但可以确定的是,无论大数据还是大模型,不只是、也不能只是技术术语,而是为了更高效推动社会发展。这是必要的约束。
而另一方面,当我们惊叹ChatGPT的惊艳时,也不能忽视其实这并不是OpenAI的第一代产品。GPT-1、GPT-2的普通表现,都经历了不同程度的业内质疑。但正依靠着坚持,才有了如今的GPT-4、以及未来的5、6、7等等。
回溯来看,AI发展的六十多年,每个阶段都有企业、团队、研发人员不被理解、负重前行,成为先驱、甚至先烈。但正是因为这些企业、团队、研发人员的付出,才迎来了当下的时刻。
在我国也是如此,有幸于商汤等公司的持续研发,才有了我们在这场大模型竞赛中、在通用人工智能大潮中,依然手握门票,甚至在中文方面,更有优势。而未来,也必然会和我们广阔的产业空间结合,为经济带来新动能,为人们带来更美好的生活。
来源:远川科技评论 微信号:kechuangych
 微信扫一扫打赏
微信扫一扫打赏 支付宝扫一扫打赏
支付宝扫一扫打赏:format(webp):quality(80)/https://assets.bohaishibei.com/2025/12/24/5_fd854.webp)
:format(webp):quality(80)/https://assets.bohaishibei.com/2025/12/24/3_caydv.webp)
:format(webp):quality(80)/https://assets.bohaishibei.com/2025/12/24/1_f39cz.webp)
:format(webp):quality(80)/https://assets.bohaishibei.com/2025/12/24/3_wkmy4.webp)
:format(webp):quality(80)/https://assets.bohaishibei.com/2025/12/24/11_4j9qv.webp)
:format(webp):quality(80)/https://assets.bohaishibei.com/2025/12/24/christmas-9187543-1280_s4kjk.webp)
