

别的不说了,差友们!马上就要过年了,差评君先送请两位咱们硬件部的同事,米罗和二狗来给大家跳个舞吧。

Ok 言归正传,今天我上班时刷的各种工作群摸鱼群里,基本都在讨论字节整的这个新模型。
原因无他,就是因为这玩意做出来的视频效果实在是太好了。
甭管是生成美少女来和你打招呼。
by 虚妄 抖音

还是让两个老头开始在屋子里大打出手都不在话下。
by 夜故事 抖音

还可以丢张咱们同事江江的照片给它,让 Seedance 2.0 直接给我们生成一段天气预报的口播画面出来。
没错,这整条里面的声音也是 AI 直接生成出来的,整个视频里的各种音效细节可以说是全给对上了。
再或者是直接丢张数学题给它,让 AI 来手写答案。
这里虽然结果写错了,但是口播的声音却是对的
太狠了字节,整个视频里,不管是人物的一致性,还是动作的流畅性还是音频的适配性,相比过去的视频生成模型都有了断崖式的提升。
工作了一天刷了一天抖音的我,已经快要分不清什么是真,什么是假的了。
不过这,还不是最让差评君感兴趣的。
素材来源于网络

真正让我好奇的是,为什么这次的新模型这么强?
在简单的体验后,差评君发现这一方面是它的模型本身能力确实够顶。
和其他常见的视频模型一样,只要随便给它一段话,Seedance 2.0 就能给你生成一段质量尚可的视频。
在上海的东方明珠塔下,生成东方明珠塔用激光攻击蜜雪冰城雪王的视频,
雪王不断躲避激光,场面十分混乱

看起来好像平平无奇,但是咱们仔细看就会发现,这个视频里,出现了不只一个镜头。
短短五秒钟的视频,镜头切换了四次。
先远景看东方明珠塔变形发光,再怼脸给雪王表情,再回到全景展示攻击。节奏跟得上、逻辑能闭环,整个段落不光好懂,甚至挺有情绪。
没错,Seedance 2.0 做出来的视频自带分镜。
经常喜欢用 AI 做视频的差友们都知道,在过去,大多数 AI 模型做出来的视频,基本上就是主打“一镜到底”。你给它写一段提示词,它还给你一段几乎固定定机位的画面。
即使有些模型有分镜吧,但他们做出来的分镜也可能不够有灵魂,变得非常奇怪。
某另外一个视频模型用相同提示词做的画面,
基本都是站桩输出

就比如上面这个视频,这画面好看吗,咱们先抛开它没识别出雪王的形象不谈,光论这个视频质量本身,确实是算不上差的。
但是这视频耐看吗?那还真不好说。
一个视频想要能引人注意,那剪辑的节奏就是一个非常非常重要的环境。
过去的 AI 想要做成刚才那样的画面,可能需要咱们预先构思每个分镜和分镜之间是如何切换的。
然后用 AI 抽卡,生成一堆一堆的关键帧,接着再在这些关键帧和关键帧之间抽卡,才能得到成吨的素材。
然后再通过人类剪辑师的发力,才能把这些成吨的素材,给变成一段好看的视频。
这一套流程下来,这就让不少想玩视频生成的新手心生畏惧了。
但这一切问题在 Seedance 2.0 这里,几乎被彻底解决了。
可以明显的看到,字节在分镜上下了不少功夫。

在不用用户特意去描述怎么分镜的情况下,自动就把分镜的活给包圆了。
整个应该镜头应该怎么切才好看给你整的明明白白,几乎是把过去半个小时的工作量给压缩成了一句话。
而且它同时还是个配乐大师,做出来的视频里,该有的音效全都有。
不管是光之巨人和怪兽大战时的嘶吼声。
还是在夜之城飙车时的引擎轰鸣声。
都可以非常精髓的还原到位。。。
甚至于你还可以直接在提示词里写清楚,你想要在这个视频里听到 AI 说什么话,就连音色也可以通过自己上传声音来制定。
另一方面,字节的产品设计也整的很牛 X。
如果说过去的 AI 视频工具用起来还有各种各样的门槛和困难的话,那么这次新发布的 Seedance 2.0 就是把这些门槛都给铲飞了。
现在,普通人都能很方便的用 AI,来做出各种华丽的画面了。
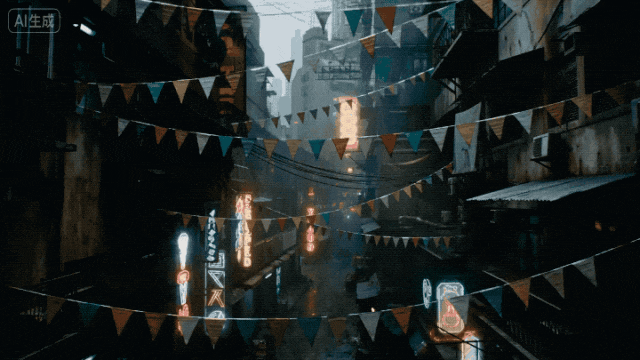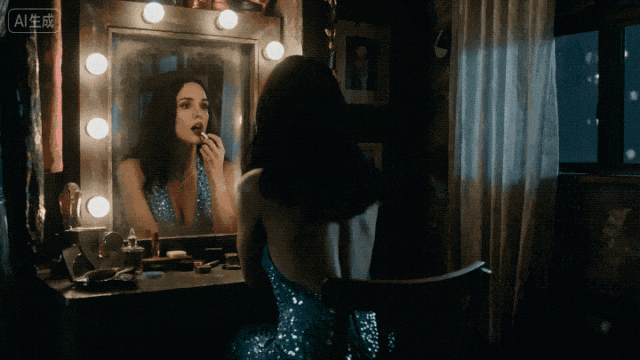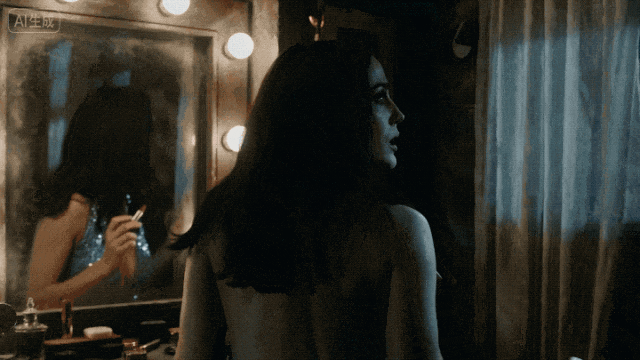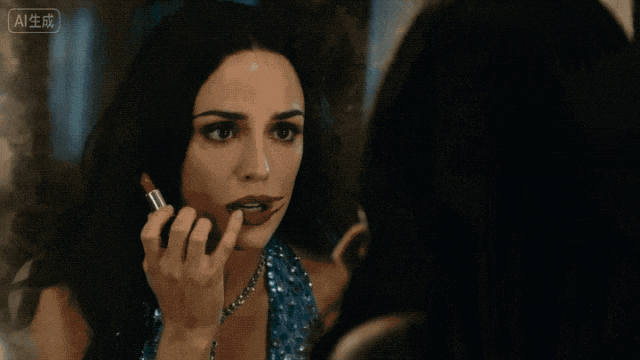
所以为什么我要给这个模型这么高的评价?不只是因为它能出好画面,而是因为它真的在认真做“产品”。
即使是零基础小白也不用害怕,这可能是目前最适合新手来玩的视频生成大模型了。
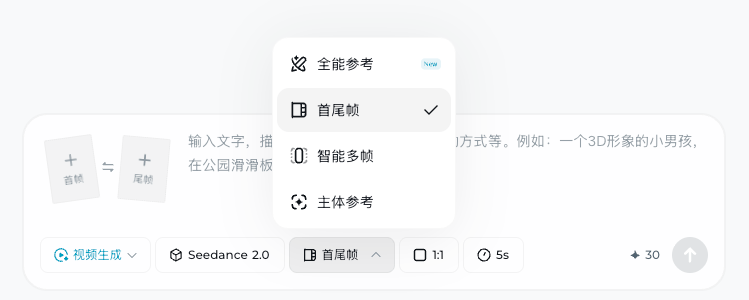
它的逻辑非常清爽,打开即梦(jimeng.jianying.com)在最底下选择“视频生成”,在边上把生成视频的模式给切换成“全能参考”,或者是“首尾帧” 之后,就可以用上最新的 Seedance 2.0 模型。
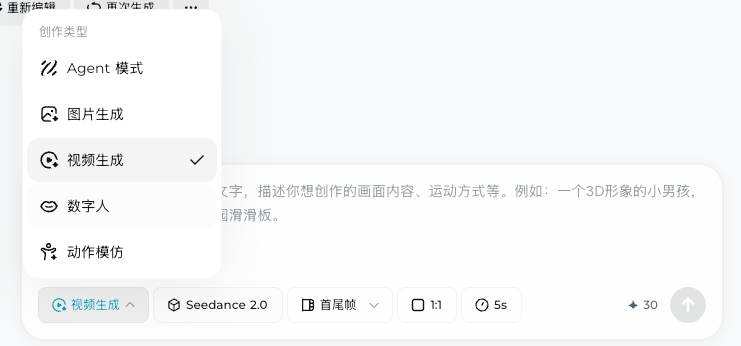
如果这里你找不到 Seedance 2.0 这个选项的话,那可能就是这个号没有被内测到,可以用小云雀 App 试试,或者过段时间等火山引擎发布了Seedance 2.0 API,就能在更多平台和APP里用到了。
没有会员也没关系,每天靠着签到的积分也可以先白嫖体验一下,如果觉得好用再充也来得及。
OK 咱们回到主题,首尾帧这个模式就不用多说,也是咱们的老朋友了,既能贴上头尾两张图片来控制 AI 的发挥,也能只贴一张开头的图片来让 AI 自己天马行空,还可以什么都不贴,打字就能直接得到我们想要的画面了。
而另外一个“全能参考” 模式就有意思了,过去咱们用 AI 做视频,遇到的最大问题是什么?
对我来说,这个最大的问题可能就是“不会形容”了。
有时候脑子里明明知道自己想要什么画面,但是在打字的时候却经常写不出来。
可一但提示词写得太抽象,那模型就给你瞎编,可写得太具体,又像在拼题。经常是提示词写到怀疑人生,还是生不出想要的质感。
而这个“全能参考” 模式就能在很大程度上避开这个问题。
在这个模式下,你可以同时从图片、视频、音频和文本这四个维度来描述你想要得到的画面。
就比如开头的跳舞小视频,我只需要同时上传米罗和二狗两位同事的照片,然后再配上一段舞蹈的视频一起给它,就能很轻松的整出来,也能基本保证人物的面部轮廓在生成的视频中不会崩溃。
这样一来,我就不需要描述具体舞蹈的姿势,也不需要描述我需要什么音乐,甚至连人物穿什么衣服都不用说,就可以直接搞出一条舞蹈视频。
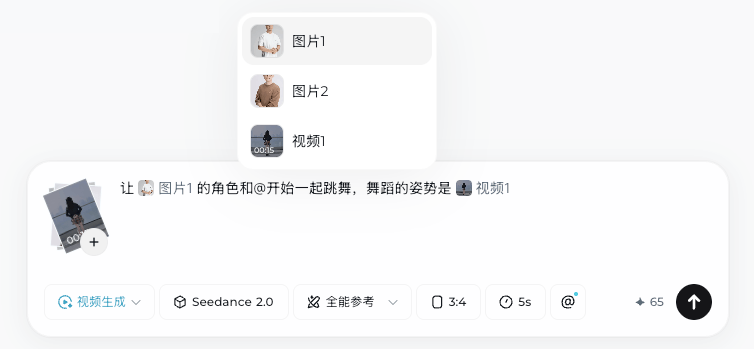
当然,想给他们换衣服也很简单,改个提示词就行了。。。
为了保护差友的双眼(为了不被打),我决定来点马赛克

在这次 Seedance 2.0 里,这个参考模式最多支持同时输入 9 张图片,3 个视频, 3 个音频(但是加起来不能超过 12 个文件)
我们可以在这个 12 个素材里任意发挥,来得到我们想要的画面,基本等于是可以傻瓜式来操作了。
说实话,它的整个产品的设计逻辑其实让我想到了另一款字节的 App —— 豆包。
这是在那产品的思路在做大模型。
不管是剪辑分镜的快速生成,还是音频画面的同步输出,再或者是方便创作的参考模式。
这三个功能的目的都很明确,希望能够降低 AI 视频生成的门槛。
下赛季你来单防詹姆斯

我很喜欢这样的产品,但到最后,话又要说回来了:
技术进步从来不是单向的狂欢。
随着 AI 生成视频的门槛越来越低,分不清 AI 视频的人,也会越来越多。
过去大家会说“眼见为实”,会说“视频是不能 P 的”。
但现在随着 AI 这一路往前奔腾进步的态势,P 个视频已经是轻轻松松的了。
像咱们这样天天和 AI 打交道,看新闻的人或许能分的出来,但是我们身边的老人孩子呢?
咱们编辑部就有个小伙伴,下午出于好玩的心态。做了一段“他自己在送外卖”的视频,结果发到家族群里之后,他妈就当真了。
吓的他赶紧解释,自己没被开除,这是 AI 做的视频,就怕下一秒直接被家长的夺命连环 call 来拷打。
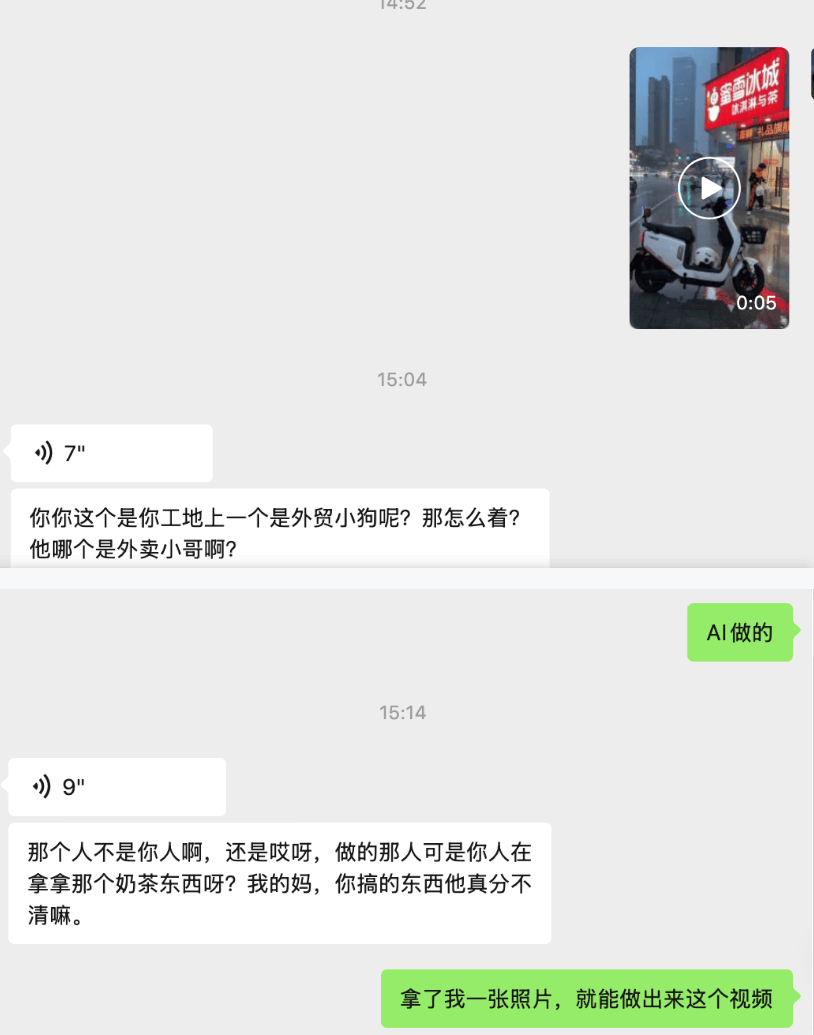
看着阿姨在群里着急的样子,差评君其实笑不出来。
因为我们突然意识到,这道横亘在现实和诈骗之间的防火墙,其实非常脆弱。

不过好在,字节好像自己也意识到了这个问题。
在今天晚上我真人照片来做尝试的时候,就遇到了好几次被屏蔽的情况。
当然这个屏蔽情况算不上稳定啊,但是能有这种“自我约束”的意识,总归是个好苗头。
因为技术跑得太快时,总会有人被落在后面,而那些人往往是我们最亲近的长辈。
但是别忘了,我们能认得出这些 AI 生成的视频,不是因为我们特殊,而是因为我们接触的早,有了抗性。
在这种情况下,我们掌握的不只是一个创作工具,更是一种沉甸甸的责任感。
也希望未来的 AI 视频,能帮我们延伸想象力的边界,而不是磨灭掉那些最基本的真实。
来源:差评XPIN
 微信扫一扫打赏
微信扫一扫打赏 支付宝扫一扫打赏
支付宝扫一扫打赏:format(webp):quality(80)/https://assets.bohaishibei.com/2026/02/09/112_28sxr.webp)
:format(webp):quality(80)/https://assets.bohaishibei.com/2026/02/09/12_t663k.webp)
:format(webp):quality(80)/https://assets.bohaishibei.com/2026/02/09/8_f649k.webp)
:format(webp):quality(80)/https://assets.bohaishibei.com/2026/02/09/7_7fckt.webp)
:format(webp):quality(80)/https://assets.bohaishibei.com/2026/02/09/6_yzauk.webp)
:format(webp):quality(80)/https://assets.bohaishibei.com/2026/02/09/5_5xc7r.webp)
